1、AIPM(artificial intelligence product manager):人工智能产品经理
2、AI(Artificial Intelligence):人工智能, 是新一轮科技革命和产业变革的重要驱动力量,是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是智能学科重要的组成部分,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能是十分广泛的科学,包括机器人、语言识别、图像识别、自然语言处理、专家系统、机器学习,计算机视觉等。人工智能大模型带来的治理挑战也不容忽视。马斯克指出,在人工智能机器学习面具之下的本质仍然是统计。 营造良好创新生态,需做好前瞻研究,建立健全保障人工智能健康发展的法律法规、制度体系、伦理道德。 着眼未来,在重视防范风险的同时,也应同步建立容错、纠错机制,努力实现规范与发展的动态平衡。
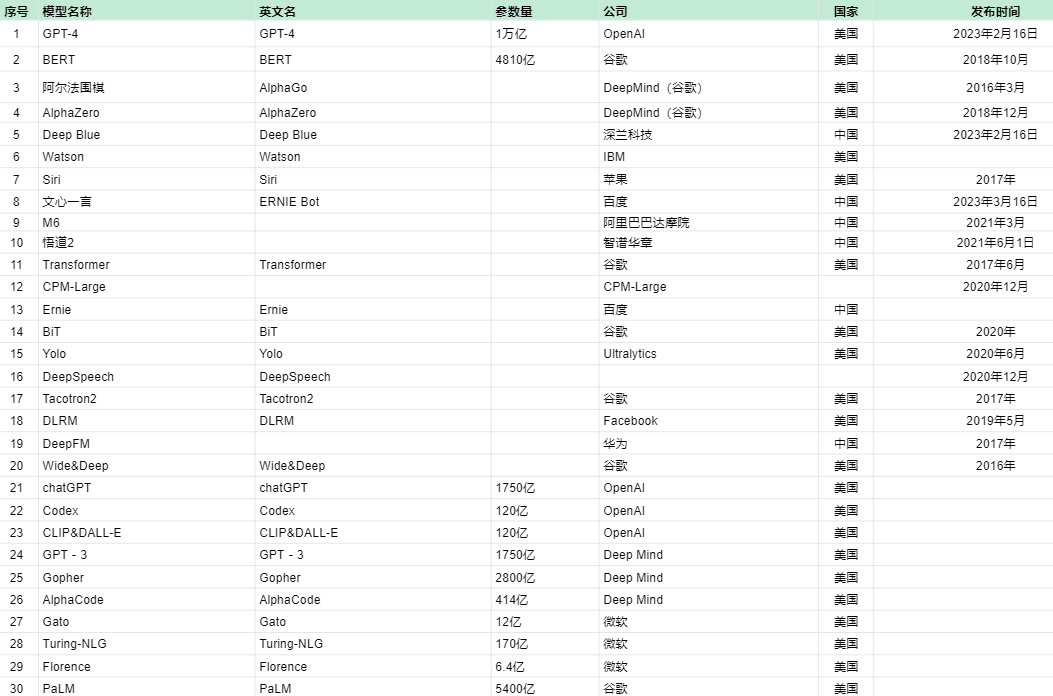
3、AI从底层到应用大概有4层:AI芯片、AI框架、AI模型、AI应用
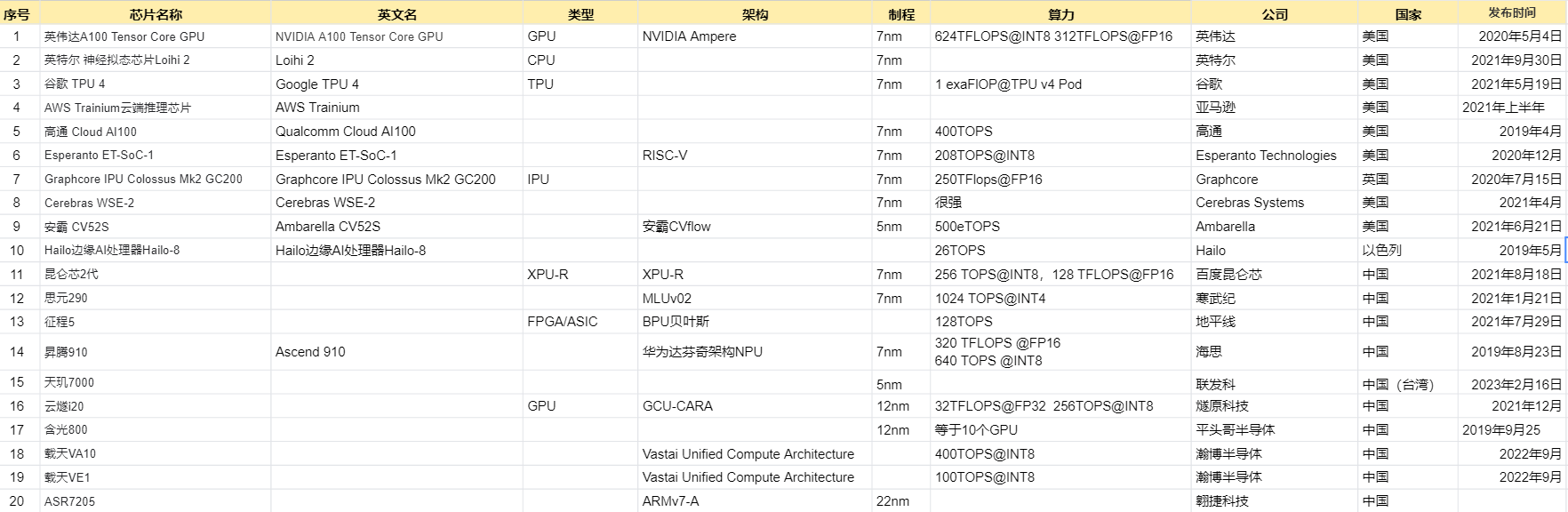
4、AI芯片:也被称为AI加速器或计算卡,即专门用于处理人工智能应用中的大量计算任务的模块(其他非计算任务仍由CPU负责)。当前,AI芯片主要分为 GPU 、FPGA 、ASIC
5、FPGA(Field Programmable Gate Array):是在PAL (可编程阵列逻辑)、GAL(通用阵列逻辑)等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。
6、PLA(Programmable Logic Array):可编程逻辑阵列,PLA 中包含了一些固定数量的与门、非门,分别组成了“与平面”和“或平面”,即“与连接矩阵”和“或连接矩阵”,以及仅可编程一次的连接矩阵(因为此处编程是基于熔丝工艺的),因此可以实现一些相对复杂的与、或多项表达式的逻辑功能。
7、GAL(genericarray logic):通用阵列逻辑,在可编程阵列逻辑的基础上强化修改而成的一种可编程逻辑器件。编程非常方便,且具有电可擦除功能,能多次编程、多次擦除。采用了输出逻辑宏单元的设计,使得电路的逻辑设计更加灵活。
8、PROM(Programmable Read-Only Memory):可编程只读存储器,与 PLA 相同,PROM 内部包含“与连接矩阵”和“或连接矩阵”,但是与门的连接矩阵是硬件固定的,只有或门的连接矩阵可编程。
9、ASIC(Application Specific Integrated Circuit):即专用集成电路,是指应特定用户要求和特定电子系统的需要而设计、制造的集成电路。 用CPLD(复杂可编程逻辑器件)和 FPGA(现场可编程逻辑门阵列)来进行ASIC设计是最为流行的方式之一,它们的共性是都具有用户现场可编程特性,都支持边界扫描技术,但两者在集成度、速度以及编程方式上具有各自的特点。
10、GPU(graphics processing unit):图形处理器,又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。GPU使显卡减少了对CPU的依赖,并进行部分原本CPU的工作,尤其是在3D图形处理时GPU所采用的核心技术有硬件T&L(几何转换和光照处理)、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬件T&L技术可以说是GPU的标志。GPU的生产商主要有NVIDIA和ATI。
11、板机:板机又称组装机、并装机。主要是以并装为主,因为一般是买会来主板一小工厂形式并装零件,组装成成品机。所以称为板机,板机存在很大的质量问题。因为在生产过程中,一般对功能不影响的部件都不会装到机里。(如:8310只有底频900Hz,没有高频1800Hz,,7610、6610、6100等不安装红外线)一般板机只对销量好的机才会生产,因为可以走得起量。(如:8210、8250、8310、7210、7250、6610、6100、T618,T628......)这些都是最常见的机款。同样板机也是只供给二手的卖家,买新机的玩家,不需要担心买到板机
12、晶体管:泛指一切以半导体材料为基础的单一元件,晶体管具有检波、整流、放大、开关、稳压、信号调制等多种功能,晶体管可用于各种各样的数字和模拟功能。晶体管是现代电器的最关键的元件之一。晶体管之所以能够大规模使用是因为它能以极低的单位成本被大规模生产。
13、晶圆(Wafer):是指制作硅半导体电路所用的硅晶片,其原始材料是硅。高纯度的多晶硅溶解后掺入硅晶体晶种,然后慢慢拉出,形成圆柱形的单晶硅。硅晶棒在经过研磨,抛光,切片后,形成硅晶圆片,也就是晶圆。国内晶圆生产线以 8英寸和 12 英寸为主。 晶圆的主要加工方式为片加工和批加工,即同时加工1 片或多片晶圆。随着半导体特征尺寸越来越小,加工及测量设备越来越先进,使得晶圆加工出现了新的数据特点。同时,特征尺寸的减小,使得晶圆加工时,空气中的颗粒数对晶圆加工后质量及可靠性的影响增大,而随着洁净的提高,颗粒数也出现了新的数据特点。
14、集成电路(integrated circuit):一种微型电子器件或部件。采用一定的工艺,把一个电路中所需的晶体管、电阻、电容和电感等元件及布线互连一起,制作在一小块或几小块半导体晶片或介质基片上,然后封装在一个管壳内,成为具有所需电路功能的微型结构;其中所有元件在结构上已组成一个整体,使电子元件向着微小型化、低功耗、智能化和高可靠性方面迈进了一大步。它在电路中用字母“IC”表示。集成电路发明者为杰克·基尔比(基于锗(Ge)的集成电路)和罗伯特·诺伊斯(基于硅(Si)的集成电路)。当今半导体工业大多数应用的是基于硅的集成电路。
15、电阻器(Resistor):在日常生活中一般直接称为电阻。是一个限流元件,将电阻接在电路中后,电阻器的阻值是固定的一般是两个引脚,它可限制通过它所连支路的电流大小。阻值不能改变的称为固定电阻器。阻值可变的称为电位器或可变电阻器。理想的电阻器是线性的,即通过电阻器的瞬时电流与外加瞬时电压成正比。用于分压的可变电阻器。在裸露的电阻体上,紧压着一至两个可移金属触点。触点位置确定电阻体任一端与触点间的阻值。端电压与电流有确定函数关系,体现电能转化为其他形式能力的二端器件,用字母R来表示,单位为欧姆Ω。实际器件如灯泡,电热丝,电阻器等均可表示为电阻器元件。电阻元件的电阻值大小一般与温度,材料,长度,还有横截面积有关,衡量电阻受温度影响大小的物理量是温度系数,其定义为温度每升高1℃时电阻值发生变化的百分数。电阻的主要物理特征是变电能为热能,也可说它是一个耗能元件,电流经过它就产生内能。电阻在电路中通常起分压、分流的作用。对信号来说,交流与直流信号都可以通过电阻。
16、电容(capacitor):两个相互靠近的导体,中间夹一层不导电的绝缘介质,这就构成了电容器。当电容器的两个极板之间加上电压时,电容器就会储存电荷。电容器的电容量在数值上等于一个导电极板上的电荷量与两个极板之间的电压之比。电容器的电容量的基本单位是法拉(F)。在电路图中通常用字母C表示电容元件。电容器在调谐、旁路、耦合、滤波等电路中起着重要的作用。晶体管收音机的调谐电路要用到它,彩色电视机的耦合电路、旁路电路等也要用到它。随着电子信息技术的日新月异,数码电子产品的更新换代速度越来越快,以平板电视(LCD和PDP)、笔记本电脑、数码相机等产品为主的消费类电子产品产销量持续增长,带动了电容器产业增长。
17、电感器(Inductor):是能够把电能转化为磁能而存储起来的元件。电感器的结构类似于变压器,但只有一个绕组。电感器具有一定的电感,它只阻碍电流的变化。如果电感器在没有电流通过的状态下,电路接通时它将试图阻碍电流流过它;如果电感器在有电流通过的状态下,电路断开时它将试图维持电流不变。电感器又称扼流器、电抗器、动态电抗器。
18、半导体(semiconductor):指常温下导电性能介于导体与绝缘体之间的材料。半导体在集成电路、消费电子、通信系统、光伏发电、照明、大功率电源转换等领域都有应用,如二极管就是采用半导体制作的器件。无论从科技或是经济发展的角度来看,半导体的重要性都是非常巨大的。大部分的电子产品,如计算机、移动电话或是数字录音机当中的核心单元都和半导体有着极为密切的关联。常见的半导体材料有硅、锗、砷化镓等,硅是各种半导体材料应用中最具有影响力的一种。
19、介质:波动能量的传递,需要某种物质基本粒子的准弹性碰撞来实现。这种物质的成分、形状、密度、运动状态,决定了波动能量的传递方向和速度,这种对波的传播起决定作用的物质,称为这种波的介质
20、氧化反应:狭义的氧化反应指物质与氧化合;还原反应指物质失去氧的作用。广义上来说,失电子为氧化反应,得电子为还原反应。有机物反应时把有机物引入氧或脱去氢的作用叫氧化;引入氢或失去氧的作用叫还原。物质与氧缓慢反应缓缓发热而不发光的氧化叫缓慢氧化,如金属锈蚀、生物呼吸等。剧烈的发光发热的氧化叫燃烧。
21、光刻(photolithography):是平面型晶体管和集成电路生产中的一个主要工艺。是对半导体晶片表面的掩蔽物(如二氧化硅)进行开孔,以便进行杂质的定域扩散的一种加工技术。
22、外延(extension):是一个逻辑学名词,是一个共相的外在内容,当一个共相不对应任何对象时,称作该共相的外延是空白的;若一个共相的外延不是空白的,则该共相对应的一切对象称作该共相的外延。
23、电路(Electric circuit):金属导线和电气、电子部件组成的导电回路称为电路。在电路输入端加上电源使输入端产生电势差,电路连通时即可工作。电路可以实现电能的传输、分配和转换,还可以实现信号的传输与处理。电路通常由电源、负载和中间环节三部分组成。电流的存在可以通过一些仪器测试出来,如电压表或电流表偏转、灯泡发光等。按照流过的电流性质,一般把它分为两种:直流电通过的电路称为“直流电路”,交流电通过的电路称为“交流电路”。
24、电子管:一种最早期的电信号放大器件。被封闭在玻璃容器(一般为玻璃管)中的阴极电子发射部分、控制栅极、加速栅极、阳极(屏极)引线被焊在管基上。利用电场对真空中的控制栅极注入电子调制信号,并在阳极获得对信号放大或反馈振荡后的不同参数信号数据。早期应用于电视机、收音机扩音机等电子产品中,后来逐渐被半导体材料制作的放大器和集成电路取代,但在一些高保真的音响器材中,仍然使用低噪声、稳定系数高的电子管作为音频功率放大器件(香港人称使用电子管功率放大器为“胆机”)。
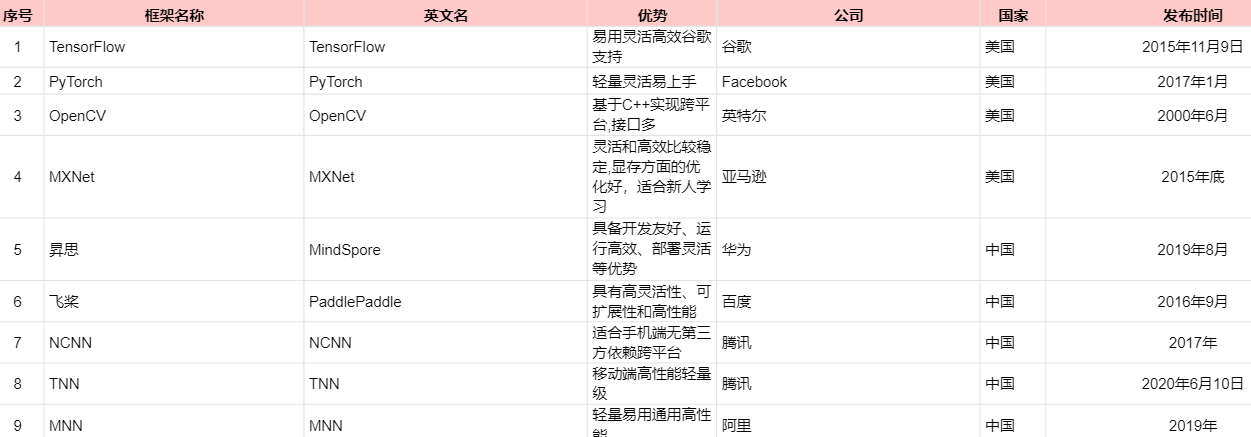
25、AI框架:和以前的PHP框架、JAVA框架、JS框架等开发框架类似,可以省去开发者很多基础工作,并且集成了很多强大的开发功能,起到事半功倍的开发效果
26、AI模型:AI模型是指运用数学、统计、计算机科学和机器学习等领域的方法,对具有一定规律性和可预测性的数据进行分析、处理、预测和优化的数学模型。简单来说,AI模型就是将“数据”转化为“智能”的一种数学模型。AI模型的设计通常涉及以下几个主要步骤:数据收集,为了构建一个有效的AI模型,需要大量的数据作为训练样本;模型训练,利用训练数据和算法对模型进行训练,使其能够自动从输入数据中学习和提取特征,并根据学习到的知识进行决策和预测。AI模型可以分为有监督学习模型和无监督学习模型两大类。有监督学习模型是一种通过对有标记(标注)数据的学习,来预测新的未标记数据的类型或属性的模型,常见的有监督学习模型包括决策树、支持向量机、神经网络等。无监督学习模型则是一种在没有明确标记的数据集上进行学习的模型,常见的无监督学习模型包括聚类、关联规则、主成分分析等。AI大模型则是指具有巨大参数量的深度学习模型,通常包含数十亿甚至数万亿个参数。这些模型可以通过学习大量的数据来提高预测能力,从而在自然语言处理、计算机视觉、自主驾驶等领域取得重要突破。总的来说,AI模型是通过训练和学习大量数据来模拟人类智能和决策能力的计算机程序,可以在各种应用领域中实现自动化和智能化的任务处理。
27、机器学习:机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。它专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径。机器学习的基本原理是使用统计学和算法来让计算机系统能够从数据中学习和改进。通过对已有数据进行模式识别和分析,使计算机能够自动完成特定任务,而无需人为编程。机器学习可以分为监督学习、无监督学习和强化学习三种主要形式。监督学习通过给计算机提供带有标签的训练数据,让它学习输入和输出之间的映射关系;无监督学习则是给计算机提供未标签的数据,让它通过自我学习和发现数据之间的隐含结构和模式;强化学习则是模型通过与环境互动来学习。机器学习的应用非常广泛,包括但不限于图像处理与识别(如人脸识别、图片分类)、自然语言处理、网络安全(如垃圾邮件检测、恶意程序/流量检测)、自动驾驶、机器人、医疗拟合预测、神经网络、金融高频交易、互联网数据挖掘/关联推荐等领域。在机器编程中,常用的编程语言包括Python、C++、Java、JavaScript以及LISP等。其中,Python因其简洁的语法和强大的库支持在机器编程,尤其是人工智能领域享有盛名。
28、深度学习:深度学习(Deep Learning)是机器学习(Machine Learning)领域中一个新的研究方向,它使机器学习更接近于最初的目标——人工智能(AI,Artificial Intelligence)。深度学习主要是通过学习样本数据的内在规律和表示层次,帮助解释诸如文字、图像和声音等数据。其目标是让机器能够像人一样具有分析学习能力,识别和理解这些复杂的数据。深度学习的核心是神经网络,由若干个层次构成,每个层次包含若干个神经元。神经元接收上一层次神经元的输出作为输入,通过加权和转换后输出到下一层次神经元,最终生成模型的输出结果。在深度学习中,反向传播算法用于优化网络参数,使得神经网络能够更好地适应数据。同时,损失函数用于衡量网络输出结果与实际标签之间的差异,常见的损失函数有交叉熵、均方误差等。深度学习的应用非常广泛,包括但不限于计算机视觉及图像识别(如人脸识别、物体检测、图像分类等)、自然语言处理(如语音识别、机器翻译、情感分析等)、语音识别及生成(如语音合成、语音识别等)、推荐系统(如商品推荐、影视推荐等)、游戏开发(如自动驾驶、智能机器人等)、医学影像识别(如肺癌、乳腺癌等疾病的诊断)、金融风控(如信用卡欺诈检测、贷款风险评估等)、智能制造(如工业设备故障诊断、质量控制等)、购物领域(如用户行为分析、价格预测等)以及基因组学(如DNA序列分析、基因表达谱预测等)。在深度学习的技术中,有几种经典的算法,包括反向传播(Backpropagation)、卷积神经网络(CNN)、循环神经网络(RNN)和生成对抗网络(GAN)等。这些算法在深度学习的各种应用中发挥着重要作用。此外,深度学习的研究也在不断发展和进步,如神经网络结构的优化、语音识别领域的新方法、图像识别领域的进展、自然语言处理领域的新应用以及自动驾驶领域的应用等。这些新的研究成果不仅提高了深度学习的性能,还降低了其计算复杂度,使得深度学习在更多领域得到应用。总之,深度学习是机器学习领域中的一个重要研究方向,它通过模拟人脑的学习过程,让机器具有更强的智能和学习能力,为人工智能的发展提供了重要的支持。
29、人工神经网络:人工神经网络(Artificial Neural Network,简称ANN)是一种模拟生物神经网络结构和功能的计算模型。其原理主要基于以下几个方面:基本单元:人工神经网络由大量的神经元(节点)组成,每个神经元代表一个特定的输出函数,称为激励函数(activation function)。这些神经元按照不同的连接方式组成网络,每个连接都代表一个对于通过该连接信号的加权值,称之为权重。信息处理:人工神经网络的信息处理过程是通过神经元的激活和连接权重来实现的。当网络接收到输入信息时,这些信息通过输入层神经元传递给隐含层神经元,然后经过多层隐含层神经元的处理,最后由输出层神经元产生输出结果。在这个过程中,神经元的激活状态取决于其输入信号和连接权重的乘积之和是否超过某个阈值。学习和训练:人工神经网络具有学习和训练的能力。通过调整神经元之间的连接权重,网络可以学习如何对输入信息进行分类、识别或预测。学习和训练过程通常采用反向传播算法(Backpropagation Algorithm),该算法通过计算网络输出与期望输出之间的误差,并逐层反向传播误差来更新连接权重,以减小网络输出误差并提高网络性能。特征提取和模式识别:人工神经网络能够自动从输入数据中提取特征并进行模式识别。在网络的学习和训练过程中,神经元之间的连接权重会不断调整,以使得网络能够更好地识别输入数据的特征。这使得人工神经网络在图像识别、语音识别、自然语言处理等领域具有广泛的应用前景。总之,人工神经网络的原理是基于生物神经网络的结构和功能来构建的,通过模拟神经元之间的连接和激活机制来实现信息的处理和识别。同时,人工神经网络具有学习和训练的能力,可以通过调整连接权重来优化网络性能。
30、逻辑回归(Logistic Regression):优点:适用于二分类或多分类问题,模型简单,易于理解和实现。缺点:对于非线性问题可能效果不佳,且容易受到特征之间的相关性影响。
31、决策树(Decision Tree):优点:易于理解和解释,能够处理非线性关系,对缺失值不敏感。缺点:容易过拟合,对连续变量的处理效果可能不佳。
32、随机森林(Random Forest):优点:通过集成多个决策树来提高预测精度,对异常值和噪声具有很好的容忍度。缺点:模型相对复杂,计算成本较高,且对于某些噪声较大的数据集可能表现不佳。
33、支持向量机(Support Vector Machine, SVM):优点:在高维空间中表现优秀,对于非线性问题可以通过核函数进行扩展。缺点:对参数和核函数的选择敏感,计算成本较高,尤其是在大数据集上。
34、K近邻算法(K-Nearest Neighbors, KNN):优点:原理简单,易于实现,无需训练过程。缺点:计算量大,对样本不平衡问题敏感,且需要存储所有训练数据。
35、神经网络(Neural Networks):优点:具有强大的学习和表示能力,可以处理复杂的非线性问题。缺点:需要大量的训练数据和时间,容易过拟合,且模型的可解释性较差。
36、循环神经网络(Recurrent Neural Networks, RNN):优点:适用于处理序列数据,如文本和语音等。缺点:对于长期依赖问题可能效果不佳,且训练难度较大。这些算法各自有其适用场景和局限性,选择合适的算法需要根据具体问题的特点和需求进行权衡。同时,随着技术的不断发展,新的算法也在不断涌现,为AI领域带来更多的可能性和挑战。在优缺点方面,需要注意的是,每种算法都有其特定的优点和局限性,没有一种算法是万能的。在实际应用中,需要根据问题的特点和需求来选择合适的算法,并进行适当的优化和调整。此外,随着数据的增长和算法的不断改进,一些算法的性能也可能会有所提升或改变。因此,对于AI算法的选择和应用,需要保持持续的学习和关注最新的研究进展。
37、RAG:检索增强生成
38、Agent:AI Agent(人工智能体)是一种能够感知环境、进行决策和执行动作的智能实体。不同于传统的人工智能,AI Agent 具备通过独立思考、调用工具去逐步完成给定目标的能力。AI Agent 和大模型的区别在于,大模型与人类之间的交互是基于prompt 实现的,用户prompt 是否清晰明确会影响大模型回答的效果。而AI Agent的工作仅需给定一个目标,它就能够针对目标独立思考并做出行动。从原理上说,AI Agent的核心驱动力是大模型,在此基础上增加规划(Planning)、记忆(Memory)和工具使用(Tool Use)三个关键组件。
39、LangChain:LangChain 是一个开源的基于 LLM 的上层应用开发框架,LangChain 提供了一系列的工具和接口,让开发者可以轻松地构建和部署基于 LLM 的应用 。LangChain 围绕将不同组件“链接”在一起的核心概念构建,简化了与 GPT-3.5、GPT-4 等 LLM 合作的过程,使得我们可以轻松创建定制的高级用例。LangChain 已经成为大模型应用开发的最主流框架(之一),23 年 1 月的众多 AI Hackathon 决赛项目使用 LangChain。2023 年融资 3000w+ 美刀(红杉)。目前, LangChain 支持 Python 和 TypeScript 两种语言。
40、AI标注:AI标注指的是一种数据预处理的方式,在这一过程中,标注员会对原始数据(如文本、图像、音频、视频等)进行高质量、高精度的处理,并为这些数据打上标签,以满足机器学习和训练的需求。具体来说,标注员会按照事先制定的标注规范和指南,通过人工或半自动的方式为数据集中的样本进行标注。这种标注过程有助于计算机模型理解数据的特征,从而提高模型在各种任务上的性能。AI标注可以应用于多个领域,如自然语言处理、计算机视觉和语音识别等。在自然语言处理领域,AI标注任务包括词性标注、命名实体识别、语义角色标注等;在计算机视觉领域,AI标注则涉及图像分类、目标检测、图像分割等任务。通过这些标注,机器学习模型能够更好地学习和理解数据,从而提升其在各类任务上的表现。近年来,AI人工数据标注得到了广泛的应用。它指的是利用人工智能技术来辅助人类标注员完成数据标注任务,这种方式可以大幅提高标注的准确性和效率,使得大规模的数据标注任务成为可能。总的来说,AI标注在机器学习和人工智能领域扮演着至关重要的角色,为模型的训练和性能提升提供了关键的数据支持。
41、AI大模型平台:AI大模型平台是一个集成了大量计算资源、数据集和模型训练工具的综合性平台。其主要目标是为开发者提供一个高效、灵活、易用的环境,使他们能够更好地构建和训练大规模的人工智能模型。AI大模型平台通常具有以下特征:参数量大:大模型在设置参数的数量上通常高达千亿,这些参数有助于模型在细节内容上进行微调,以提升某一方面的权重,从而尽可能地提升内容的准确性。数据量大:大模型的训练内容多且复杂,包括用于学习的标注数据和用于训练的未标记数据。通过更大体量数据的训练,能有效提升人工智能的智能程度。结构复杂:大模型的内部网络结构十分复杂,并且有意模仿人类神经结构排列,使得人工智能的输出逻辑更加符合人类的思想,提升其知识迁移的能力。预训练与微调:大模型的训练阶段较一般模型更多,分为预训练与微调两个阶段。前者是对无标签数据的学习,后者则是对学习内容的巩固,确保其训练成果。AI大模型平台支持的应用场景非常广泛,包括但不限于图像识别、自然语言处理、语音识别、推荐系统、金融领域、医疗健康以及农业等。在图像识别方面,大模型可以应用于安防、医疗、自动驾驶等领域;在自然语言处理方面,大模型可以进行文本分类、情感分析、机器翻译等任务,应用于智能客服、新闻资讯、搜索引擎等场景;在推荐系统方面,大模型可以分析用户行为数据,为用户提供个性化的推荐内容,应用于电商、社交媒体、视频平台等场景。随着技术的不断发展,AI大模型平台正趋于通用化与专用化,垂直行业将是大模型的主战场。同时,AI大模型平台也在广泛开源,小型开发者可以调用大模型能力来提升开发效率。此外,AI高性能芯片的不断升级也在推动AI大模型产业生态体系的完善。总的来说,AI大模型平台为人工智能的发展提供了强大的支持,推动了各个领域的技术进步和应用创新。百度在AI大模型平台方面拥有显著的布局和成果。其中,百度智能云千帆大模型平台是百度在AI大模型领域的一个重要平台。这个平台不仅提供基于文心一言或者第三方开源大模型的大模型服务,还提供全套工具链和开发环境,旨在帮助企业开发自己的专属大模型。在千帆大模型平台的基础上,百度还推出了千帆大模型平台2.0,这个版本拥有预置最多的大模型和数据集、最丰富最全面的工具链、最佳算力效能以及最完备的大模型安全方案。千帆平台纳管的国内外主流大模型达到42个,还预置了41个高质量有行业特色的数据集,预装了知识问答、客服对话、代码助手等10个精选应用范式,这些都能大幅降低企业使用、训练和推理大模型的门槛。此外,百度AI开放平台也是全球领先的人工智能服务平台,其中文心大模型是其重要的一部分。文心大模型中的ERNIE 3.5是目前百度智能云千帆大模型平台上最受欢迎的基础大模型之一。综上,百度在AI大模型平台方面的布局广泛且深入,不仅提供了丰富的模型和服务,还致力于通过技术创新和工具链的完善,推动AI大模型在各个领域的应用和发展。
42、AI prompt:在人工智能(AI)领域,特别是在自然语言处理(NLP)中,Prompt指的是给定的一个或一系列的文本输入,旨在引导或触发AI模型生成特定的输出或响应。Prompt在不同的上下文中可以有不同的用途和形式。例如,它可以用来“预热”语言模型,为其提供背景信息,从而生成连贯和相关的文本。它也可以作为执行特定任务的指令,或者指定生成文本的样式、主题或结构。在信息检索或对话系统中,Prompt还可以帮助细化搜索结果或引导对话的方向。此外Prompt的应用场景非常丰富。在聊天机器人领域,Prompt可以用来生成更加人性化、智能的对话;在搜索引擎领域,Prompt可以用来优化搜索结果的质量;在智能客服领域,Prompt可以用来提高客服的响应速度和解决率。甚至在艺术领域,Prompt也可以用来生成艺术作品,如诗歌、绘画等。总的来说,Prompt是人工智能领域中的一种重要技术,通过它,我们可以更好地让机器理解人类的语言,从而提高交互效果。
43、目前国内的大模型都有哪些:目前国内的大模型主要包括以下几种:百度-文心一言:作为科技大厂中首个发布的生成式AI产品,百度“文心一言”于2023年3月16日开启邀测,并在同年10月发布了文心一言最新迭代产品——文心一言4.0。它在自然语言处理领域具有显著实力,并在实际应用中展现出高价值。智谱AI-智谱清言:成立于2019年的智谱AI是国内最早一批研发大模型的企业,由清华大学知识工程实验室(KEG)技术成果转化。其大模型在To B层面与多家国内互联网巨头、政企达成合作。抖音-云雀:抖音集团(前字节跳动)在2023年8月17日宣布开始对外测试AI对话产品“豆包”。百川智能-百川:百川智能成立于2023年,由搜狗创始人王小川创立。经过半年多时间发展,百川智能发布了多款开源可免费商用大模型及闭源大模型。华为云盘古大模型:华为在华为开发者大会上正式发布了人工智能(AI)大模型华为云盘古大模型3.0。此外,还有通义千问、Moonshot(Kimi)等大模型也具有一定的行业影响力。根据最新的评测结果,Baichuan 3在国内大模型中表现出色,其文科、理科能力均衡,且在逻辑推理能力上超越了部分国外大模型。请注意,以上列举的大模型仅为部分代表,随着技术的不断发展,未来还将有更多的大模型涌现。
44、AI数字人:AI数字人(Artificial Intelligence Digital Human)是一种采用人工智能技术和仿真技术创建的虚拟人物。它结合了人类外貌、语音和认知能力,能够与人类进行交流和互动。以下是关于AI数字人的详细介绍:制作过程:AI数字人的制作需要经历数据采集与处理、三维建模、骨骼绑定与动画制作等步骤。数据采集包括人物的外貌特征、动作、语言等,这些数据可以通过摄像头捕捉、扫描仪扫描等多种途径进行采集。完成数据采集与处理后,使用专业的三维建模软件将二维图像转换为三维模型,为AI数字人创建一个具有真实感的外观。接下来,进行骨骼绑定和动画制作,使模型可以跟随骨骼的运动而产生相应的动作。应用领域:AI数字人逐渐被政务、文旅、展馆展厅、博物馆、数字会议、金融、校园等领域广泛应用。例如,在展厅中,AI数字人可以作为“数字迎宾员”或“虚拟讲解员”,为参观者提供展馆信息、园区介绍、展厅展览等信息的讲解。在金融领域,AI数字人可以作为数字化员工,通过人机对话形式向用户展示金融环境、发展历史、发展计划等。发展趋势:随着技术的不断进步,AI数字人的仿真程度和应用场景将不断扩展。未来,AI数字人将具有更高的智能水平,能够更自然地与人类进行交流和互动。同时,随着虚拟现实、增强现实等技术的发展,AI数字人将在更多领域得到应用,为人们带来更加丰富的数字化体验。总之,AI数字人是一种结合了人工智能技术和仿真技术的虚拟人物,具有广泛的应用前景和发展潜力。
45、传统软件和机器学习的逻辑差异:互联网时代,产品经理的工作是针对现有业务进行分析,并根据该业务过程设计出合理的系统处理逻辑,开发工程师根据设计好的系统处理逻辑进行产品实现。因此,传统软件从输入到输出过程的运算是经过设计的,且是固定的、明确的;与互联网产品、传统软件产品不同,人工智能产品是根据已有数据自动化构建逻辑结构。人工智能产品通过机器学习算法反复从数据中进行学习,不需要告诉计算机业务逻辑,人工智能算法就可以找到隐含在其中的规律和意义。人工智能产品将训练数据(输入数据+结果数据)输入人工智能算法中,得出一个模型,并将新数据输入这个模型中进行运算,进而得出结果,实现预算和判断,通过数据和算法得出的模型替代了由产品经理或需求分析师设计的软件逻辑结构。
46、机器学习的学习模式:根据训练的方式不同,机器学习分为监督学习、无监督学习、半监督学习和强化学习四大学习模式。这四种学习模式的根本区别是数据内容的不同和训练模式的不同。监督学习(也称有监督学习):通过有标签的数据进行训练,得到一个模型,通过该模型对未知数据进行处理。无监督学习:事先没有任何训练数据样本,而是通过算法对数据进行分析建模,找到其中的规律。半监督学习:半监督学习训练中使用的数据,只有一部分是标注过的,而大部分是未标注的。强化学习:强化学习也是使用未标注的数据,但是可以通过某种方法知道你是离正确答案越来越近还是越来越远。
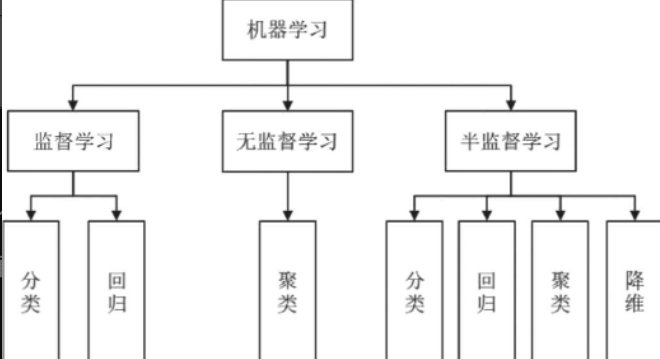
47、机器学习可以解决哪些问题:归纳概括可分为分类、回归、聚类、降维等,在解决这些问题时有很多算法,常见的为监督学习算法(如SVM、KNN、决策树、朴素贝叶斯、逻辑回归、线性回归、人工神经网络等)和无监督学习算法(如聚类、EM算法等)。(1)分类(Classification):给定一个样本特征,我们要预测其对应的标注值,如果属性值是离散的,那么这就是一个分类问题。(2)回归(Regression):给定一个样本特征,我们要预测其对应的标注值,如果属性值是连续的,那么这就是一个回归问题。(3)聚类(Clustering):给定一组样本特征,我们不需要预测其对应的标注值,而是想发掘这组样本在空间的分布,如分析哪些样本离得近、哪些样本离得远,那么这就是一个聚类问题。(4)降维(Dimensionality Reduction):给定一组样本特征,如果需要用维数低的子空间来表示原来高维的特征空间,那么这就是降维问题。作为产品经理,需要对机器学习的学习模式有深入的了解,还需要了解各类学习模式主要是用来做什么的,这样才可以与工程师进行有效沟通。各种问题的应用领域及算法如下表格所示

48、监督学习的过程:例如,用户上传一张照片,系统需要识别这张照片是不是其本人。该用户上传的照片可能是全身照,也可能是半身照,甚至照片中只有一只眼睛的特写。第一步,数据的生成和分类。首先要收集足够多的关于该用户的照片,全身、半身、正面、侧面,只要是该用户的影像都存在一个组内,这个组叫作训练集。训练集是用来进行训练的。其次再准备一组照片,这组照片中有一部分是该用户的,另外一部分则是他人的,这个组叫作验证集。验证集用来检验训练好的算法模型能否认出该用户。验证集作为输入,得到一些输出,照片中有该用户输出为1,没有该用户则输出为0。第二步,训练。通过人工神经网络进行训练时,训练集中的每一个图像都会成为人工神经网络的输入,经过人工神经网络中每一层神经元的运算,进行特征提取,当计算完成后会得到输出,观察输出的是1还是0。第三步,验证。第一组中的数据全部用完后,用第二组中的数据验证训练得到的模型的准确率。这个过程涉及超参优化、选择激活函数等。第四步,封装应用。一旦数据验证的指标达到了预期的指标,模型就训练完成。此时可以将该模型封装为接口,集成到软件中。软件通过界面与用户交互,当用户将照片上传后,软件会自动调用该接口完成计算,并将结果返还给软件程序界面。人工智能产品经理不一定要了解设计算法,也不一定要去具体实现算法,但一定要懂得算法的内容、特点,以及算法能达到的目标。
49、如何优化超参数:优化超参数是机器学习和深度学习模型训练过程中的一个重要步骤,它旨在找到一组最优的超参数设置,使得模型在给定任务上达到最佳性能。以下是一些常见的超参数优化方法:手动调整:初步尝试:根据经验和领域知识,对模型的超参数进行手工设定,并观察模型在验证集上的表现,然后调整超参数并重复此过程。分析学习曲线:通过绘制训练和验证误差随训练迭代次数的变化图,可以分析模型是否过拟合或欠拟合,从而指导超参数的调整。网格搜索(Grid Search):定义一个超参数网格,包含所有要尝试的超参数组合。对网格中的每一个超参数组合训练模型,并记录验证集上的性能。选择验证集上表现最好的超参数组合。随机搜索(Random Search):随机采样超参数空间中的点,而不是像网格搜索那样穷举所有可能的组合。通过随机抽样更多的可能性,有时比网格搜索更高效,尤其是当有些超参数的影响较小的时候。贝叶斯优化(Bayesian Optimization):建立一个代理模型(如高斯过程)来估计超参数空间中不同点的性能。根据代理模型选择下一个最有希望的超参数组合进行尝试,同时更新代理模型。通过迭代优化,尽可能少的评估次数找到全局最优超参数。基于梯度的优化(Gradient-based Hyperparameter Tuning):对于某些类型的超参数,可以通过自动微分库计算超参数梯度,实现类似于训练模型参数的梯度下降优化。L-BFGS、Adam等优化算法也可用于超参数优化。进化算法(Evolutionary Algorithms):将超参数视为个体,通过模拟自然选择和遗传变异的过程来寻找最优解。如遗传算法(Genetic Algorithm)、粒子群优化(Particle Swarm Optimization)等。超参数调优工具:使用开源库如scikit-optimize、Optuna、Hyperopt等,它们提供了内置的各种优化策略。迁移学习和元学习:利用在类似任务上预先训练的模型的超参数作为起点,然后在新任务上进行微调。集成方法:同时训练多个具有不同超参数配置的模型,然后使用集成技术(如投票、平均)融合他们的预测。在实际应用中,可以结合以上多种方法,结合具体项目的资源限制和时间成本,选择适合的超参数优化策略。同时,交叉验证和提前停止(Early Stopping)等技术也被广泛用于避免过拟合和节省计算资源。
50、大模型中激活函数是个啥?:在深度学习中,激活函数是用于对神经网络中神经元的输出进行非线性变换的函数。它的作用是将神经元的输入映射到一个非线性的输出范围,从而增加神经网络的表达能力和灵活性。常见的激活函数包括 Sigmoid 函数、Tanh 函数、ReLU 函数等。其中,Sigmoid 函数将输入映射到[0,1]之间的范围,常用于二分类问题;Tanh 函数将输入映射到[-1,1]之间的范围,常用于回归问题;ReLU 函数则是一种简单的阈值函数,当输入大于 0 时输出为输入本身,否则输出为 0。随着深度学习的发展,出现了一些新的激活函数,如 LeakyReLU、ELU 等,它们在一定程度上解决了传统激活函数的一些问题,如梯度消失和神经元坏死等。除了传统的激活函数,近年来还出现了一些基于注意力机制的激活函数,如 Scaled Dot-Product Attention(SDPA)等。这些激活函数可以更好地处理序列数据,提高模型的性能和泛化能力。在选择激活函数时,需要考虑模型的任务、数据集的特点、模型的复杂度等因素。不同的激活函数可能会对模型的性能产生不同的影响,因此需要进行实验和调参来选择最适合的激活函数。总的来说,激活函数是深度学习中非常重要的组成部分,它的选择和设计对模型的性能和泛化能力有着重要的影响。
51、生成式对抗网络(GAN):无监督学习中的生成式对抗网络(GAN,Generative Adversarial Networks)是一种深度学习模型,由两个神经网络组成:生成器(Generator)和判别器(Discriminator)。这两个网络彼此竞争,通过不断的对抗训练来优化自己,从而推动整个模型学习。生成器(Generator):生成器的目标是将随机噪声(通常是从正态分布或均匀分布中采样的向量)转换成逼真的数据样本,如图像、音频、文本等。这个过程可以理解为生成器学习了数据的分布,并尝试创建与真实数据相似的新样本。在初始阶段,生成器的输出可能是随机的,但随着训练的进行,它会逐渐生成更逼真的数据,以欺骗判别器。判别器(Discriminator):判别器的任务是对输入的数据样本进行分类,即判断它是真实数据还是由生成器产生的假数据。判别器需要尽可能准确地判断数据来源,以指导生成器生成更真实的数据。GAN的优化过程是一个“二元极小极大博弈”问题。在训练过程中,固定其中一方(判别网络或生成网络),更新另一个模型的参数,然后交替迭代。最终,生成模型能够估测出样本数据的分布,生成的数据样本与真实数据样本难以区分。GAN的出现对无监督学习,特别是图片生成的研究起到了极大的促进作用。GAN已经从最初的图片生成,被拓展到计算机视觉的各个领域,如图像分割、视频预测、风格迁移等。此外,GAN还可以与其他深度学习技术结合,如卷积神经网络(CNN),形成深度卷积生成对抗网络(DCGAN),进一步提高生成性能。然而,无监督学习在GAN中也面临一些挑战,如数据预处理、模型过拟合和训练时间等。为了克服这些挑战,研究者们提出了许多GAN的变体和改进方法,以提高其性能和稳定性。
52、无监督学习-聚类:目前,无监督学习常见的场景是聚类。聚类是根据数据的相似性原则,把数据分为多种类别的过程。评估两个不同样本之间的“相似性”,通常使用的方法是计算两个样本之间的“距离”。当然,距离的计算方法有很多,在使用不同的方法计算时,会直接关系聚类结果的优势,常用的距离的计算方法有欧氏距离、曼哈顿距离、马氏距离等。欧氏距离是最常用的,也是最容易理解的距离度量方法,即两点之间的距离;曼哈顿距离也称“城市街区的距离”,如同在各类地图应用中计算两点间的距离,需要根据道路的方向进行计算;马氏距离表示的是数据的协方差距离,是一种与尺度无关的度量方式。马氏距离会先将样本点的各个属性标准化,再计算样本间的距离。
53、CLIP:随着人工智能技术的不断发展,我们看到了一个又一个令人惊叹的成果。其中,AIGC(人工智能生成内容)领域的一项突破性技术,CLIP,已经成为众多研究者关注的焦点。本文将深入探讨CLIP技术的核心原理、技术细节,以及它在各种实际应用中的表现。首先,我们来解析一下"CLIP"的含义。这是一个由OpenAI研发的多模态模型,它集成了计算机视觉(Computer Vision)和自然语言处理(Natural Language Processing)的功能。通过将图像和文本这两种不同模态的信息进行统一处理,CLIP能够理解并回答关于图像的问题,或者根据文本描述来识别对应的图像。这一特性使得CLIP在图像识别、文本理解、以及图像与文本的跨模态检索等领域具有广泛的应用前景。接下来,我们深入探讨CLIP的技术细节。CLIP的核心在于其强大的多模态特征提取能力。它通过联合训练一个视觉Transformer和一个Transformer的编码器-解码器结构,以同时理解并处理图像和文本信息。此外,CLIP还采用了一种称为"Contrastive Language–Image Pre-training"的训练方法,这种方法使得CLIP能够从大量的无标签数据中学习有用的特征。有了对CLIP技术的深入理解,我们再来看看它在各种实际应用中的表现。在教育领域,CLIP可以用于创建智能化的图像识别工具,帮助学生更好地理解复杂的科学概念。在医疗领域,CLIP可以帮助医生快速识别X光片、MRI等医学影像中的异常,提高诊断的准确性和效率。在娱乐产业,CLIP可以用于电影、游戏等内容的自动生成,提供更加丰富和多样的内容选择。此外,CLIP还可以应用于智能家居、智能客服、智能安防等领域。例如,在智能家居中,CLIP可以帮助用户通过语音或文字指令来控制家里的电器设备;在智能客服中,CLIP可以帮助企业自动回答客户的问题,提升客户服务的效率和质量;在智能安防中,CLIP可以用于监控视频的分析和识别,提高公共安全保障能力。总的来说,CLIP作为AIGC领域的一项重要技术,其强大的多模态处理能力和广泛的应用前景使其成为人工智能领域的研究热点。随着技术的不断进步和应用场景的不断拓展,我们相信CLIP将会在更多领域发挥其巨大的潜力,为人类带来更多的便利和创新。
54、Stable Diffusion:Stable Diffusion(稳定扩散,后续简称sd)是一款基于深度学习的文本到图像生成模型,于2022年由stability.ai发布,一经发布就带来了巨大反响,更为可贵的是其开源精神,这也使得这个产品能够持续快速的迭代,也成为了第一批具备商用级别能力的AIGC产品。这个模型主要通过给定的文本提示词(text prompt)生成匹配的图像。例如,输入文本提示词“一只可爱的猫咪”,稳定扩散会输出带有这样一只猫咪的图片。图像生成的发展:在Stable Diffusion诞生之前,计算机视觉和机器学习方面最重要的突破是 GAN(Generative Adversarial Networks 生成对抗网络)。GAN让超越训练数据已有内容成为可能,从而打开了一个全新领域——现在称之为生成建模。然而,在经历了一段蓬勃发展后,开始暴露出一些瓶颈和弊病,大家倾注了很多心血努力解决对抗性方法所面临的一些瓶颈,但是鲜有突破,GAN由此进入平台期。GAN的主要问题在于:图像生成缺乏多样性,模式崩溃,多模态分布学习困难,训练时间长,由于问题表述的对抗性,不容易训练,另外,还有一条基于似然(例如,马尔可夫随机场)的技术路线,尽管已经存在很久,但由于对每个问题的实施和制定都很复杂,因此未能产生重大影响。近几年,随着算力的增长,一些过去算力无法满足的复杂算法得以实现,其中有一种方法叫“扩散模型”——一种从气体扩散的物理过程中汲取灵感并试图在多个科学领域模拟相同现象的方法。该模型在图像生成领域展现了巨大的潜力,成为今天Stable Diffusion的基础。扩散模型扩散模型是一种生成模型,用于生成与训练数据相似的数据。简单的说,扩散模型的工作方式是通过迭代添加高斯噪声来“破坏”训练数据,然后学习如何消除噪声来恢复数据。一个标准扩散模型有两个主要过程:正向扩散,反向扩散,在正向扩散阶段,通过逐渐引入噪声来破坏图像,直到图像变成完全随机的噪声。在反向扩散阶段,使用一系列马尔可夫链逐步去除预测噪声,从高斯噪声中恢复数据通过缓慢添加(去除)噪声来生成样本的正向(反向)扩散过程的马尔可夫链,对于噪声的估计和去除,最常使用的是 U-Net。该神经网络的架构看起来像字母 U,由此得名。U-Net 是一个全连接卷积神经网络,这使得它对图像处理非常有用。U-Net的特点在于它能够将图像作为入口,并通过减少采样来找到该图像的低维表示,这使得它更适合处理和查找重要属性,然后通过增加采样将图像恢复回来。
55、ControlNet:如果要画一幅画,一方面是构图,一方面是风格,现在的AI绘画,就是炼丹。需要通过各种 prompt 来控制画面的构图和风格。鉴于prompt 的专业性与复杂性,产生了两个模型: ControlNet就是用来控制构图的,LoRA就是用来控制风格,。还有一个风格迁移的模型shuffle,此外,SD1.5也能生成好的图像。
56、Imagen:Imagen是一个文本到图像的扩散模型,由Google大脑团队研究所开发。Imagen通过创新的设计,摈弃了需要预训练视觉-语言模型的繁琐步骤,直接采用了T5等大规模语言模型作为文本编码器,与扩散模型有机结合,完成了从文本到图像的直接关联映射。这种结合语言模型与扩散模型的端到端方式,充分利用了T5作为纯文本模型的优势,包括参数规模的可拓展性和丰富的文本预训练数据,比依赖视觉信息的CLIP等模型更加灵活和直接。Imagen的结果表明,单纯依靠语义理解力极强的语言模型就可以完成逼真的图像合成,而不需要额外引入视觉模型作为“桥梁”。这为未来在相同框架下,继续扩大语言模型规模与语义理解能力,达到文本到图像生成更上一层楼,提供了可能性与期待。Imagen模型是一个文本到图像的生成模型,它首先使用一个大型的固定T5-XXL编码器将输入文本编码成嵌入向量。然后,一个条件扩散模型将文本嵌入映射成一个64×64像素的图像。最后,Imagen利用文本条件的超分辨率扩散模型将图像从64×64像素上采样到256×256像素,然后进一步上采样到1024×1024像素。文本编码:使用冻结的文本编码器将文本转换为嵌入向量。 文本到图像扩散模型:使用条件扩散模型将文本嵌入转换成一个初步的低分辨率图像(64×64像素)。 超分辨率扩散模型:通过一系列超分辨率模型,逐步将图像的分辨率提高,最终生成高分辨率的图像(1024×1024像素)。
57、Dreambooth:一个创新的人工智能引导创作(AIGC)平台,这个平台可以帮助用户在简单的三个步骤中完成自由绘画的创作。
58、vLLM:vLLM 是虚拟大型语言模型的简称,它是一个由 vLLM 社区维护的开源代码库。该代码库有助于大型语言模型(LLM)更高效地大规模执行计算。具体而言,vLLM 是一种推理服务器,可通过更好地利用 GPU 内存来加快生成式 AI 应用的输出速度。
59、Ollama:Ollama是一个专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计的开源框架。它允许开发者在本地环境中方便地运行和测试不同的语言模型;优点是简化部署、跨平台支持、轻量级与可扩展、活跃的社区支持
60、模型蒸馏:模型蒸馏(Model Distillation)是一种深度学习技术,旨在将大型复杂模型的知识转移到一个较小的模型中。其目标是在保持高性能的同时,显著降低模型的复杂性和计算资源需求。模型蒸馏通常用于提升运行效率,使得模型更适合在资源有限的环境(如移动设备和边缘计算)中使用。
61、TFLOPS(Tera FLOPS): FLOPS(floating-point operations per second)每秒执行1万亿次浮点运算,主要用于评价GPU的算力
62、TOPS:TOPS:每秒执行1万亿次运算,通常用于评价处理器的算力或INT8的算力
45、AI数字人:
45、AI数字人:
45、AI数字人:
45、AI数字人:
45、AI数字人:
45、AI数字人:
45、AI数字人:
45、AI数字人:
45、AI数字人:
45、AI数字人:
45、AI数字人:
45、AI数字人:
45、AI数字人:
45、AI数字人:
45、AI数字人:
45、AI数字人:
45、AI数字人:
45、AI数字人:
81、人工智能神经网络
82、人工智能神经网络
83、人工智能神经网络
84、人工智能神经网络
85、人工智能神经网络
86、人工智能神经网络
87、人工智能神经网络
88、人工智能神经网络
89、人工智能神经网络
90、人工智能神经网络